-
Chapter 3: Training the Image ClassifierRaywenderlich/Machine Learning by Tutorials 2020. 5. 7. 15:42
이전 장에서 훈련된 모델(trained model)을 사용하여 Core ML과 Vision으로 이미지를 분류(classify)하는 방법을 살펴 보았다. 그러나 모델(model)이 원하는 것을 정확하게 수행하지 못하거나, 자신만의 데이터와 범주(categories)를 사용해야 하는 경우처럼 다른 사람의 모델(model)을 사용하는 것만으로 충분하지 않은 경우가 많으므로 모델(model)을 훈련시키는 방법을 아는 것이 좋다.
이 장에서는 자신만의 모델(model)을 만드는 법을 배운다. 기계 학습(machine learning) 전문가(experts)가 사용하는 일반적인 도구(common tools)와 라이브러리(libraries)의 사용법을 학습한다. Apple은 Xcode에서 모델(model)을 생성하기 위한 기계 학습 프레임 워크(machine learning framework)로 Create ML을 제공한다. Create ML을 사용하여, 간식(snack) 모델(model)을 학습하는 방법을 배운다.
The dataset
모델을 훈련시키기 전에 데이터가 필요하다. 기계 학습(machine learning)은 많은 예제에서의 "규칙(rules)"을 배우기 위해 모델(model)을 훈련시키는 모든 것이다.
이미지 분류기(image classifier)에서 예제는 이미지가 된다. 여기서는 20가지의 간식(snacks)을 구분할 수 있는 이미지 분류기(image classifier)를 훈련시킬 것이다.
가능한 범주(categories)는 다음과 같다 :
Healthy: apple, banana, carrot, grape, juice, orange, pineapple, salad, strawberry, watermelon
Unhealthy: cake, candy, cookie, doughnut, hot dog, ice cream, muffin, popcorn, pretzel, wafflesnacks-download-link.webloc을 더블 클릭하여 기본 다운로드 위치에 간식(snack) 데이터 세트를 다운로드한 후, 압축 해제한다. 그리고 해당 폴더를 데이터 세트(dataset) 폴더로 이동한다. 여기에는 모델(model)을 훈련시킬 이미지가 포함되어 있다.
이 데이터 세트에는 약 7,000 개의 이미지가 있으며, 각 범주(categories)에 대해 대략 350개의 이미지가 있다.

데이터 세트(dataset)는 train, test, val의 세 폴더로 나누어 진다. 모델 훈련에는 훈련(train) 폴더의 4,800개 훈련 세트(training set) 이미지만을 사용한다.
val과 test 폴더(각각 950 개)의 이미지는 훈련된 모델(model)이 얼마나 잘 작동하는지 측정하는 데 사용된다. 이것을 각각 검증 세트(validation set)와 테스트 세트(test set)라고 한다. 모델(model) 품질에 대한 신뢰있는 추정(estimate)을 위해, 교육 중에 검증 세트(validation set)나 테스트 세트(test set) 이미지를 사용하지 않는 것이 중요하다. 차후에 이 부분을 더 자세히 설명한다.
교육 이미지(training images)의 몇 가지 예시는 다음과 같다 :

보다시피 이미지는 다양한 종류의 모양과 크기로 제공된다. 폴더(folder) 이름은 범주(class)의 이름으로 사용되며, 레이블(label) 또는 대상(target)이라고도 한다.
Create ML
이제 Create ML를 사용하여 간식(snacks) 데이터 세트(dataset)로 다중 클래스 분류기(multi-class classifier)를 훈련(train)한다.
Xcode 메뉴에서 Xcode ▸ Open Developer Tool ▸ Create ML를 선택한다 :

Finder 창(window)이 열리면, New Document를 선택한다. Choose a Template 창(window)에서 Image ▸ Image Classifier를 선택하고 다음(Next)를 누른다.

분류기의 이름을 MultiSnacks로 지정하고, 다음(Next)을 누른다.

이미지 분류기(image classifier)를 저장할 장소를 선택한 다음, 생성(Create)을 클릭하여 분류기(classifier) 창(window)을 표시한다.

첫 번째 단계는 교육 데이터(Training Data)를 추가하는 것이다 : Choose ▸ Select Files... 를 클릭한 후, snacks/train 으로 이동한 후, 열기(Open)를 클릭한다.

창(window)이 업데이트 되어 범주(classes)의 수와 교육 데이터(training data) 항목을 표시하고, 상태(state)는 Ready to train이 표시된다. 교육(Train) 버튼을 클릭한다 :

창에는 Activity가 표시된다 : 1 단계(Step)는 특징(features)을 추출(extract)하는 것으로 표시되며, 처리된 이미지 수를 보여주는 진행 표시 바(progress bar)가 있다.

2 단계는 훈련이며, 각 반복(iteration)에 대해 훈련 정확도(Training accuracy), 검증 정확도(Validation accuracy)를 표시하는 그래프(graph)가 표시된다. 교육이 완료되면 20개 범주(classes)에 대한 정밀도(Precision)와 재현율(Recall)이 나열된 계량 분석표(Metrics table)가 제공된다.

4,800개의 이미지가 실제 RAM보다 더 많은 메모리를 차지할 수 있기 때문에, Create ML이 어떻게 모든 훈련 데이터(training data)를 메모리에 로드 할 수 있는지 궁금할 것이다. Create ML은 데이터를 MLDataTable 구조(structures)로 로드하고, 이미지 메타 데이터(metadata)만 메모리에 유지한 다음, 필요에 따라 이미지를 직접 불러온다(loads). 이는 많은 양의 데이터를 포함한 매우 큰 MLDataTable을 가질 수 있다는 의미이다.
Precision and recall
Create ML은 각 범주(class)에 대한 정밀도(precision)와 재현율(recall)을 계산하여, 어떤 범주(classes)가 더 나은 결과를 보여주는 지 판단하는 데 유용하다. 여기 결과에서 이 값들은 대부분 100%에 가깝다.
정밀도(precision) : 모델(model)이 "사과"라고 예측하는 모든 이미지 중 98%가 실제 사과이다. 거짓 양성(false positives)이 많지 않으면 정밀도(precision)가 높아지고, 어떤 것을 '사과'로 잘못 분류한다면 낮아진다. 어떤 것이 실제 "X" 범주(class)가 아니지만 모델(model)이 "X"로 잘못 판단하는 경우 거짓 양성(false positive)이 된다.
재현율(recall) : 총 사과 수에서 모델(model)이 발견한 사과 수를 계산한다. 위의 경우에서는 "사과" 이미지를 100% 찾아냈다. 재현율(recall)은 거짓 음성(false negatives)을 보여준다. 재현율(recall)이 낮으면 실제로 많은 사과를 잘못 분류한 것이다. 어떤 것이 실제로 "X" 범주(class)이지만, 모델(model)이 다른 범주(class)로 잘못 판단하는 경우 거짓 음성(false negative)이 된다.
정밀도와 재현율 위키백과 : https://ko.wikipedia.org/wiki/%EC%A0%95%EB%B0%80%EB%8F%84%EC%99%80_%EC%9E%AC%ED%98%84%EC%9C%A8
정밀도(Precision)와 재현율(Recall)이 높을수록 좋으며, 95% 이상이면 매우 뛰어난 결과이다. 예를 들어 "사과" 범주(class) 정밀도(precision)가 98%이라면, 모델(model)이 사과라고 판단한 50개의 이미지 중 약 1개 정도가 실제로는 사과가 아니라는 의미이다. 위의 결과에서는, 모델(model)이 테스트 세트에서 모든 당근 이미지를 찾았음을 의미한다.
정밀도(precision)가 가장 낮은 최악의 범주(classes)는 "사과"(98%)와 "케이크"(98%)이다. 최악의 재현율(recall) 범주(classes)는 “아이스크림”(98 %)이다. 모델(model)을 개선하기 위해서는 더 많고 나은 이러한 범주(classes)의 교육 이미지를 수집하는 등의 방법으로 더 주의를 기울여야 한다.
모델 훈련과 검증은 임의성(randomness)이 있기 때문에, 정밀도(precision)와 재현율(recall)은 위의 결과와 다를 수 있다.
How we created the dataset
좋은 교육 데이터를 수집하는 것은 매우 많은 시간이 필요할 수 있으며, 종종 기계 학습(machine learning)에서 가장 비용이 많이 드는 단계로 간주되기도 한다. 인터넷에서 사용할 수 있는 데이터가 풍부함에도 불구하고, 데이터 세트(dataset)를 자주 조정해야 하는 경우가 있다 : 불량 데이터를 제거 또는 정리하거나 분류 오류(classification errors)를 수정하려면 데이터 항목을 수동으로 검토해야 한다.
이 데이터 세트의 이미지는 Google Open Images Dataset에서 가져왔으며, 여기에는 수천 개의 범주(categories)로 구성된 9백만 개 이상의 이미지를 포함하고 있다. Open Image 프로젝트(project)는 실제 이미지를 호스팅(host)하지 않으며, 이러한 이미지의 URL만 호스팅(host)한다. 대부분의 이미지는 Flickr에서 가져온 것이며, 모두 Creative Commons license(CC BY 2.0)이다. storage.googleapis.com/openimages/web/index.html에서 해당 Open Images Dataset를 확인할 수 있다.
간식 데이터 세트(dataset)를 만들기 위해, 먼저 Open Images에서 수천 개의 범주(classes)를 살펴보고 20가지 범주(categories)의 건강한(healthy), 그리고 건강에 해로운(unhealthy) 간식(snack)을 선택했다. 그런 다음 모든 이미지에 대한 주석(annotations)을 다운로드했다. 해당 주석(annotations)에는 이미지 범주(class) 등의 메타 데이터(metadata)가 포함되어 있다. Open Images의 이미지는 여러 객체(object)를 포함할 수 있으므로, 다중 범주(multiple classes)를 가질 수도 있다.
20개의 선택된 범주(classes) 각각에 대해 무작위로(randomly) 이미지 URL을 선택하고, Python 스크립트(script)를 사용하여 다운로드했다. 이미지 중 일부는 더 이상 사용할 수 없거나 질이 좋지 않았고, 잘못된 범주(category)로 분류(mislabeled)되어 있는 경우도 있었기 때문에 다운로드한 이미지를 직접 정리하였다.
데이터 정리(clean up)를 위해 수행해야 할 작업은 다음과 같다 :
- Open Images의 이미지에는 사과와 바나나 등 두 개 이상의 객체(object)가 포함되어 있는 경우가 많으며, 분류기(classifier)는 이미지 당 하나의 레이블(label)만 예측하기 때문에 이런 이미지는 분류기(classifier)를 훈련시키는 데 사용할 수 없다. 이미지는 사과 또는 바나나 중 하나만 포함해야 하며, 그렇지 않으면 학습 알고리즘(learning algorithm)을 혼동하게 될 것이다. 따라서 하나의 주요 객체만 포함하고 있는 이미지를 사용한다(We only kept images with just one main object).
- 때로는 범주(categories)를 판단하기 모호한(blurry) 이미지가 있을 수 있다. 케이크 범주(category)의 많은 이미지가 컵케익인데, 이는 머핀과 매우 유사하다. 이러한 모호한 이미지를 데이터 세트에서 제거한다(we removed these ambiguous images from the dataset). 여기서는 컵케익이 케이크 범주(category)가 아닌 머핀 범주(category)에 속한다.
- 선택한 이미지가 해결하려는 문제에 의미가 있는 것인지 확인한다(We made sure the selected images were meaningful for the problem you’re trying to solve). 간식 분류기(snacks classifier)는 가정이나 사무실에서 찾을 수 있는 일반적인 음식들에 대해 사용하도록 고안되었다. 그러나 Open Images의 바나나 범주(category)에는 녹색 바나나 더미가 달린 바나나 나무의 이미지가 많이 있다. 이는 분류기(classifier)가 인식하기(recognize) 원하는 종류의 바나나가 아니다.
- 다양한 이미지를 포함해야 한다(we included a variety of images). 요리 책에서나 찾을 수 있을 것 같은 "완벽한(perfect)" 이미지뿐 아니라, 다양한 배경, 조명 조건, 사람이 있는 이미지를 포함한다(집이나 사무실에서 앱을 사용할 가능성이 높으며, 찍은 사진에는 사람이 있을 것이다).
- 신경망(neural network)이 이미지의 크기를 299x299 픽셀(pixel)로 조정하기 때문에, 관심 객체가 매우 작은 이미지는 버린다(We threw out images in which the object of interest was very small). 매우 작은 객체(object)는 크기가 몇 픽셀에 불과할 뿐이며, 모델(model)이 무언가를 배우기에는 너무 작다.
좋은 결과를 얻은 데이터 세트(dataset)가 나올 때까지 이미지를 다운로드하고 선별(curating)하는 과정을 여러 번 반복했다. 데이터를 개선함으로써 모델(model)의 정확도(accuracy)도 향상되었다.
이미지 분류기(image classifier)를 훈련시킬 때, 이미지가 많을 수록 좋다. 그러나 여기서는 데이터 세트(dataset) 범주(category) 당 약 350개의 이미지로 제한하여, 다운로드 횟수와 교육 시간을 짧게 유지한다. ImageNet과 같은 인기있는 데이터 세트(datasets)는 범주(category) 당 1,000개 이상의 이미지가 있으며, 그 크기도 수백 기가 바이트(gigabytes)이다.
최종 데이터 세트(dataset)에는 범주(category) 당 350개의 이미지가 있으며, 교육(training) 이미지 250개, 유효성 검사(validation) 이미지 50개, 테스트(test) 이미지 50개로 나눠진다. 프레첼과 팝콘같은 일부 범주(categories)는 Open Images에서 적합한 이미지를 찾기 힘들기 때문에 그 수가 더 적다.
각 범주(category)가 정확히 동일한 수의 이미지를 가질 필요는 없지만, 그 차이가 너무 크지 않아야 한다. 그렇지 않으면 모델(model)이 다른 범주보다 해당 한 범주(class)를 더 많이 배울 것이다. 이러한 데이터 세트를 불균형(imbalanced)하다고 하며, 이를 제대로 활용하기 위해서는 특별한 기술이 필요하다.
가장 작은 쪽(side)이 256 픽셀(pixel)이 되도록 모든 이미지의 크기를 조정했다. 이것은 반드시 필요한 것은 아니지만, 다운로드 크기가 더 작아지고, 교육 속도가 조금 더 빨라진다. 또한 일부 Python 이미지 로더(image loaders)가 해당 이미지에 대해 경고를 표시하기 때문에, 이미지에서 EXIF 메타 데이터(metadata)를 제거했다. EXIF에 이미지의 방향(orientation) 정보가 포함되어 있기 때문에 이 메타 데이터(metadata)를 제거하는 경우, 일부 이미지가 거꾸로 보일 수 있다.
데이터 세트(dataset)를 만드는 작업은 시간이 오래 걸리지만 매우 중요하다. 데이터 세트(dataset)의 품질이 높지 않으면, 모델(model)이 원하는 것을 제대로 학습할 수 없다. 최고의 알고리즘(algorithms)보다 최고의 데이터(data)가 더 중요할 수 있다.
CC BY 2.0 라이센스(license) 규칙을 준수하기만 하면, 해당 간식(snack) 데이터 세트(dataset)의 이미지를 자유롭게 사용할 수 있다. 파일 이름은 Google Open Images 주석(annotations)에 사용한 것과 동일한 ID를 갖는다. 포함된 credits.csv 파일을 사용하여 이미지의 원본 URL을 조회할 수 있다.
Transfer learning
Create ML은 현재 전이 학습(transfer learning)을 사용하여 모델(model)을 훈련시킨다. 전이 학습(transfer learning)은 다른 작업에 대해 훈련된 다른 모델(model)의 지식을 재사용(reusing)하여, 모델(model)을 빠르게 훈련시키는 영리한 방법이다.
이전 장에서 사용한 HealthySnacks와 MultiSnacks 모델(model)은 SqueezeNet으로 만들었다. Create ML에서 사용하는 기본 모델(model)은 SqueezeNet이 아닌 VisionFeaturePrint_Screen으로, iOS 기기에서 고품질의 결과를 얻기 위해 Apple에서 특별히 설계한 모델(model)이다.
VisionFeaturePrint_Screen은 엄청난 수의 범주(classes)를 인식하기 위해 방대한(ginormous) 데이터 세트(dataset)에 대한 사전 교육을 받았다. 이는 이미지에서 어떤 특징(features)을 찾아야 하는지, 그리고 이러한 특징들(features)을 조합하여 어떻게 이미지를 분류(classify)하는지 등을 포함한다. 데이터 세트(dataset)에 대한 거의 대부분의 교육 시간은 모델(model)이 이미지에서 2,048개의 특징(features)을 추출하는 데 소요된다. 여기에는 하위 수준 가장자리(low-level edges), 중간 수준 모양(mid-level shapes) 및 작업별 높은 수준(task-specific high-level)의 특징(features)이 포함된다.
특징(features)이 추출되면, Create ML은 이미지를 20개의 범주(classes)로 분리하기 위해 로지스틱 회귀(logistic regression) 모델(model)을 훈련시킨다. 여기에는 비교적 적은 시간밖에 소비되지 않는다. 분산된 점(scattered points)에 직선(straight line)을 긋는 것과 비슷하지만, 2차원이 아닌 2,048 차원에 대해 실행된다.
전이 학습(transfer learning)은 학습 시키는 데이터 세트(dataset)의 특징(features)이 해당 모델 학습에 사용된 데이터 세트의 특징(features)과 상당히 유사한 경우에만 성공적으로 작동한다. ImageNet에서 사전 훈련(pre-trained)된 모델(model)로 전이 학습(transfer learning)을 진행할 경우, 연필 그림이나 현미경 이미지를 제대로 학습하지 못할 수 있다.
A closer look at the training loop
전이 학습(transfer learning)은 신경망(neural network)을 처음부터(from scratch) 훈련하는 것보다 시간이 덜 소요된다. 그러나 전이 학습(transfer learning)의 작동 방식을 명확하게 이해하기 전에, 먼저 신경망(neural network)을 훈련시키는 것이 무엇을 의미하는지 알아야 한다.

신경망(neural network)이 훈련되는(trained) 방식은 다음과 같다 :
- 임의의 작은 숫자로 신경망의 "두뇌"를 초기화한다(Initialize the neural network’s “brain” with small random numbers). 이것이 훈련되지 않은 모델(untrained model)이 무작위 추측(random guesses)을 하는 이유이다 : 그 지식(knowledge)은 말 그대로 무작위(random)이다. 이 숫자들을 모델(model)의 가중치(weights) 또는 학습된 매개 변수(learned parameters)라고 한다. 훈련(Training)은 이러한 가중치(weights)를 임의의(random) 숫자에서 의미있는(meaningful) 숫자로 바꿔나가는 과정(process)이다.
- 신경망이 모든 훈련 예제에 대해 예측하도록 한다(Let the neural network make predictions for all the training examples). 이미지 분류기(image classifier)의 경우, 훈련 예제(training examples)는 이미지이다.
- 예측을 예상 답변과 비교한다(Compare the predictions to the expected answers). 분류기(classifier)를 훈련할 때 일반적으로 "대상(targets)"이라고 하는 예상 답변(expected answers)은 훈련 이미지의 범주(class) 레이블(label)이다. 대상(targets)은 예측(predictions)이 예상 답변(expected answers)과 얼마나 다른지 측정하는 "오류(error)" 또는 손실(loss)을 계산하는 데 사용된다. 손실(loss)은 가중치(weights)의 특정 구성(configuration)에 대한 최소값(minimum value)을 갖는 다차원(multi-dimensional) 함수로, 훈련의 목표는 손실(loss)이 최소값에 매우 가까워지게 하는 최상의 가중치(weight) 값을 결정하는 것이다. 가중치(weights)가 임의의 값인 훈련되지 않은 모델(untrained model)에서는 손실(loss)이 크다. 이 손실 값(loss value)이 낮을수록 모델(model)은 더 많은 것을 알게 된다.
- 가중치(weights)를 개선하고(improve) 오류(error)를 줄이기 위해, 손실 함수의 기울기를 계산한다(calculate the gradient of the loss function). 이 기울기(gradient)는 각 가중치(weight)가 손실(loss)에 얼마나 기여했는지 알려준다. 기울기(gradient)를 사용하면 다음 번에는 손실(loss)이 약간 줄어들도록 가중치(weight)를 수정할 수 있다. 이 수정 단계(correction step)를 경사 하강(gradient descent)이라고하며, 훈련 중에 여러 번 발생한다. 이것은 모델(model)의 지식(knowledge)을 올바른 방향으로 약간 움직여, 다음 번에는 훈련 이미지에 대해 조금 더 정확한 예측(predictions)을 할 수 있게 한다.
대규모의 데이터 세트(datasets)의 경우, 모든 학습 데이터(training data)를 사용해 기울기(gradient)를 계산하는 데에 오랜 시간이 소요된다. 확률적 경사 하강(SGD, stochastic gradient descent)은 무작위로 선택된 훈련 데이터(training data)의 미니 배치(mini-batches)에서 기울기(gradient)를 추정(estimates)한다. 이는 선거를 앞두고 유권자들을 대상으로 여론조사를 하는 것과 같다 : 표본(sample)이 전체 데이터 세트(dataset)를 대표(representative)하는 경우, 여론 조사 결과는 최종 결과를 정확하게 예측(predict)한다. - 교육 세트의 모든 이미지에 대해 이 과정을 수백 번 반복(repeat this process hundreds of times for all the images in the training set)하려면, 2 단계로 이동한다. 각 훈련 단계(training step)마다 모델(model)이 조금씩 개선된다. 학습 매개 변수(learned parameter)는 임의의(random) 숫자에서 과제 해결에 더 적합한 숫자로 수정된다. 시간이 지남에 따라, 모델(model)은 더 나은 예측(predictions)을 하는 방법을 배운다.
확률적 경사 하강은 다소 무차별(brute-force)적인 접근 방식(approach)이지만, 현실적으로(practical) 심층 신경망(deep neural networks)을 훈련시키는 유일한 방법이다. 그러나 불행하게도 속도가 느리다. SGD가 안정적으로 작동하도록 학습된 매개 변수(learned parameters)는 한 번에 약간만 조정할 수 있으므로, 모델(model)이 무엇을 배우도록 하려면 많은 교육 단계(수십 만 번 이상)가 필요하다.
학습되지 않은 모델(model)이 임의 가중치(random weights)로 초기화(initialized) 되는 것을 확인했다. 이러한 모델(model)이 이미지 분류(image classification)와 같은 원하는 작업을 학습하려면, 많은 훈련 데이터(training data)가 필요하다. 이미지 분류기(Image classifiers)는 종종 범주(class) 당 수천 개의 이미지 데이터 세트(datasets)를 학습한다. 이미지가 너무 적으면 모델(model)은 아무것도 배울 수 없다. 기계 학습(Machine learning)은 데이터에 굶주려 있다.
이는 딥 러닝 모델(deep learning model)을 처음부터(from scratch) 훈련시키는 작업의 두 가지 큰 단점이다 : 많은 데이터가 필요하고 속도가 느리다.
Create ML은 보다 현명한 접근 방식을 사용한다. Create ML은 임의의(random) 숫자만 있는 훈련되지 않은 모델(untrained model)로 시작하는 대신, 이미 대규모 데이터 세트(dataset)로 성공적으로 훈련된 신경망(neural network)을 가져 와 자신의 데이터로 미세 조정(fine-tunes)한다. 여기에는 전체가 아닌 일부 모델(model)의 일부(portion)만 교육하는 것이 포함된다. 이 지름길(shortcut)은 신경망(neural network)이 다른 종류의 문제에서 배운 지식(knowledge)을 자신의 작업으로 가져오기(transferring) 때문에 전이 학습(transfer learning)이라 한다. 처음부터(from scratch) 모델(model)을 훈련시키는 것보다 훨씬 빠르고, 잘 작동할 수 있다. 이는 "더 열심히가 아니라, 더 현명하게 일하라(work smarter, not harder)!"라는 말에 맞는 기계 학습(machine learning)이다.
Create ML에서 사용하는 사전 훈련된(pre-trained) VisionFeaturePrint_Screen 모델(model)은 이미 많은 음식과 음료 이미지를 학습했기 때문에, 앱에서 사용할 이미지 종류에 대한 많은 지식을 가지고 있다. 전이 학습(transfer learning)을 사용하면 이런 기존 지식(existing knowledge)을 활용할 수 있다.
전이 학습(transfer learning)을 사용할 때는 특성(feature) 추출(extraction)에 사용할 기본 모델(base model)을 선택해야 한다. 지금까지 본 두 가지 기본 모델은 SqueezeNet과 VisionFeaturePrint_Screen 이다. Turi Create는 교육 데이터(training data)를 분석(analyzes)하여 가장 적합한 기본 모델을 선택한다. 현재 Create ML의 이미지 분류기(image classifier)는 항상 VisionFeaturePrint_Screen 기본 모델(base model)을 사용한다. 특징(feature)이 2,048개로 많기 때문에, 특징(feature) 추출(extraction) 과정(process)에 시간이 걸린다. VisionFeaturePrint_Screen의 장점은 iOS 12와 Vision 프레임 워크(framework)의 일부이므로, 이를 기반으로 구축한 모델은 따로 기본 모델(model)을 포함할 필요가 없기 때문에 크기가 킬로바이트(KB, kilobytes) 단위로 작다는 것이다. 단점은 Create ML로 훈련된 모델(model)은 iOS 11나 Android와 같은 다른 플랫폼에서는 작동하지 않는다.
이 사전 훈련된(pre-trained) 기본 모델(base model)은 20가지 특정 유형의 간식(snacks)을 알지 못하기 때문에, 이를 간식 탐지기(detector) 앱에 직접 연결할 수는 없지만, 특징 추출기(feature extractor)로 사용할 수 있다.
What is feature extraction?
기계 학습(machine learning)은 흥미롭게 여기는 어떤 종류의 데이터 항목인 "특징(features)" 에서 발생한다. 사진의 픽셀(pixel)을 특징(features)으로 사용할 수 있지만, 이전에 설명한 것처럼 개별 RGB 값은 이미지에 어떤 종류의 객체(object)가 있는지에 대해 많은 것을 말하지 않는다.
VisionFeaturePrint_Screen은 이해하기 어려운 픽셀(pixel) 특징(features)을, 이미지의 객체(object)를 훨씬 더 잘 설명하는 특징(features)으로 변환한다.
이것이 전에 언급했던 파이프 라인(pipeline)이다. 그러나 VisionFeaturePrint_Screen의 출력(ouput)은 이미지에 각 범주(class)의 객체(object)가 포함되어 있을 가능성을 나타내는 확률 분포(probability distribution)가 아니다.
VisionFeaturePrint_Screen의 출력(ouput)에는 더 많은 특징(features)이 있다.

각 입력(input) 이미지에 대해 VisionFeaturePrint_Screen은 2,048개의 숫자 목록(list)을 생성한다. 이 숫자는 높은 수준(high level)에서 이미지의 내용을 나타낸다. 이 숫자의 의미가 무엇인지 정확히 말로 표현하기는 쉽지 않지만, 각각의 이미지를 2,048차원 공간의 한 점이라고 생각하면 비슷한 특성(feature)을 가진 이미지들이 함께 묶인다(grouped).
예를 들어, 2,048개의 숫자 중 하나는 간식(snacks)의 색상을 나타낼 수 있으며, 오렌지와 당근은 그 차원(dimension)에서 매우 유사한 값을 가질 것이다. 또 다른 특징(feature)은 객체(object)가 얼마나 긴지(elongated) 나타낼 수 있으며 바나나, 당근, 핫도그는 오렌지, 사과보다 더 큰 값(values)을 가질 것이다.
반면에 사과, 오렌지, 도넛은 간식(snack)의 "둥근(round)"정도의 차원(dimension)에서 더 높은 점수를 얻는 반면, 와플은 해당 차원(dimension)에서 더 낮은 점수를 받는다(해당 특징(feature)의 음수 값(negative value)은 객체가 원형(roundness)이 아닌 사각형(squareness)임을 의미한다).
모델(model)은 위의 예시와 달리 보통 해석할 수 없는 것이 대부분이지만, 다음과 같은 아이디어(idea)를 얻을 수 있다 : 이 새로운 2,048개의 특징(features)은 이미지의 객체(object)를 실제 특성(characteristics)으로 설명하는데에 픽셀(pixel) 강도(intensities)보다 훨씬 유익하다. 그러나 VisionFeaturePrint_Screen은 자체 데이터 세트(dataset)에 대해 훈련되지 않았기 때문에, 이 2,048차원 공간(dimensional space)에서 간단하게 선(초평면(hyperplane))을 그려 이미지를 원하는 다른 범주(classes)로 분리할 수 없다. VisionFeaturePrint_Screen은 20개가 아닌 1000개의 범주(classes)가 있는 ImageNet으로 학습되었다.
VisionFeaturePrint_Screen은 훈련(training) 이미지에서 더 유용한 특징(features)을 생성하는 데 유용하지만 이러한 이미지를 분류(classify)하려면, 데이터를 20가지 유형의 간식(snack)에 대한 확률 분포(probability distribution)로 해석할 수 있는 20차원 공간(dimensional space)으로 한 번 더 변환해야 한다.
Create ML은 이 2,048개의 숫자를 로지스틱 회귀(logistic regression)라는 새로운 기계 학습 모델(machine learning model)의 입력(input)으로 사용한다. Create ML은 150,000개의 특징(features)을 가진 이미지에 대한 복잡한 모델(model)을 교육하는 대신, VisionFeaturePrint_Screen에서 추출한 상위 2,048개의 특징(features)으로 훨씬 간단한 모델(model)을 교육한다.
Logistic regression
Create ML이 모델 교육을 완료하면, 상태(status)는 훈련(training)에 걸린 시간을 표시한다. 대부분의 시간은 특징 추출(extracting features)에 소비되었다.
Create ML을 실행한 컴퓨터 환경에 따라 시간이 달라진다. 또한 훈련되지 않은 모델(이 경우에는 로지스틱 회귀(logistic regression))은 임의의 숫자로 초기화(initialized)되므로, 훈련(training) 과정에서 결과가 달라질 수도 있다.
Create ML 훈련(trains)의 해결방법은 로지스틱 회귀(logistic regression)라는 분류기(classifier)를 사용하는 것이다. 이것은 오래된 기계 학습 알고리즘(old-school machine learning algorithm)이지만 여전히 매우 유용하다. 오늘날에도 가장 많이 사용되는 ML 모델(model)이라 할 수 있다.
선형 회귀(linear regression)라는 다른 유형의 회귀(regression)에 익숙 할 수 있다. 이것은 그래프(graph)의 점을 통과하는 선을 맞추는 행위로, 최소 제곱법(least squares)이라고도 한다.

로지스틱 회귀(Logistic regression)는 동일한 작업을 수행하면서 범주를 나눈다. 선의 한쪽에 있는 모든 점은 A 범주(class)에 속하고, 다른 쪽에 있는 모든 점은 B 범주(class)에 속한다. 공간을 두 개의 범주(classes)로 나누기 위해 선(line)을 긋는다.
2,048차원을 표현할 수 없으므로, 위에서는 로지스틱 회귀(logistic regression)를 2차원으로 표현했지만, 알고리즘(algorithm)은 입력(input) 데이터의 크기에 관계없이 동일한 방식으로 작동한다. 실제 결정 경계(decision boundary)는 선(line)이 아닌, 고차원 객체(high-dimensional object)인 초평면(hyperplane)이다. 그러나 인간은 2-3차원 이상을 이해하기 어렵기 때문에, 직선(straight line)으로 시각화(visualize)하는 것을 선호한다.
Create ML에서는 2개 이상의 범주(classes)를 처리하는 알고리즘(algorithm)으로, 로지스틱 회귀(logistic regression)를 약간 변형(variation)한 다항 로지스틱 회귀(multinomial logistic regression)를 사용한다.
2,048차원(dimensional)의 특징(features)을 20개의 범주(classes)로 나누는 구분선을 그릴 수 있는 공간으로 변환하기 위해
로지스틱 회귀(logistic regression) 알고리즘(algorithm)을 교육(training)하는 것은 원시 픽셀(raw pixel) 값이 아닌, 이미지에 대한 의미있는 특징(features)에서 시작하기 때문에 상당히 쉬운 일이다.
로지스틱 회귀(logistic regression)의 작동 방식이 궁금하다면, 일종의 변형(transformation)을 이해해야 한다. 로지스틱 회귀(logistic regression) 모델(model)은 범주(class) A에 속하는 점은 음수(negative) 값으로 변환(transformed)하고, 범주(class) B의 점은 양(positive)수 값으로 변환하여 선에 대한 "계수(coefficients)"(학습 된 매개 변수(learned parameters))를 찾으려고 한다. 변환된 점이 양수(positive)인지 음수(negative)인지에 따라 범주(class)가 결정된다. 점이 더 모호할수록, 즉 점이 결정 경계(decision boundary)에 가까울수록 변환된 값이 0에 가까워진다. 다항 로지스틱 회귀(multinomial logistic regression)는 이를 확장하여 두 개 이상의 범주(classes)를 허용한다. 차후에 이를 계산하는 수학에 대해 살펴 본다. 지금은 이 알고리즘(algorithm)이 다른 범주(classes)에 속하는 점을 구분하는 최선의 직선(line) / 초평면(hyperplane)을 찾는다는 것을 이해하면 충분하다.
Looking for validation
데이터 세트에 4,838 개의 이미지가 있지만 Create ML은 그 중 95%만 교육(training)에 사용한다.
훈련 중에 모델(model)의 성능을 주기적으로 확인하는 것이 좋다. 이를 위해 Create ML은 교육 예제 중 약 5%인 240개의 이미지를 제외하여 별도로 설정한다. 이 이미지들은 로지스틱 분류기(logistic classifier)를 훈련(train)시키지 않고, 모델(model)의 성능을 평가하고(evaluate) 로지스틱 회귀(logistic regression)의 설정을 조정하는 데만 사용한다.
출력(output)에는 훈련 정확도(training accuracy)와 검증 정확도(validation accuracy)를 나타내는 그래프(graph)가 있다.
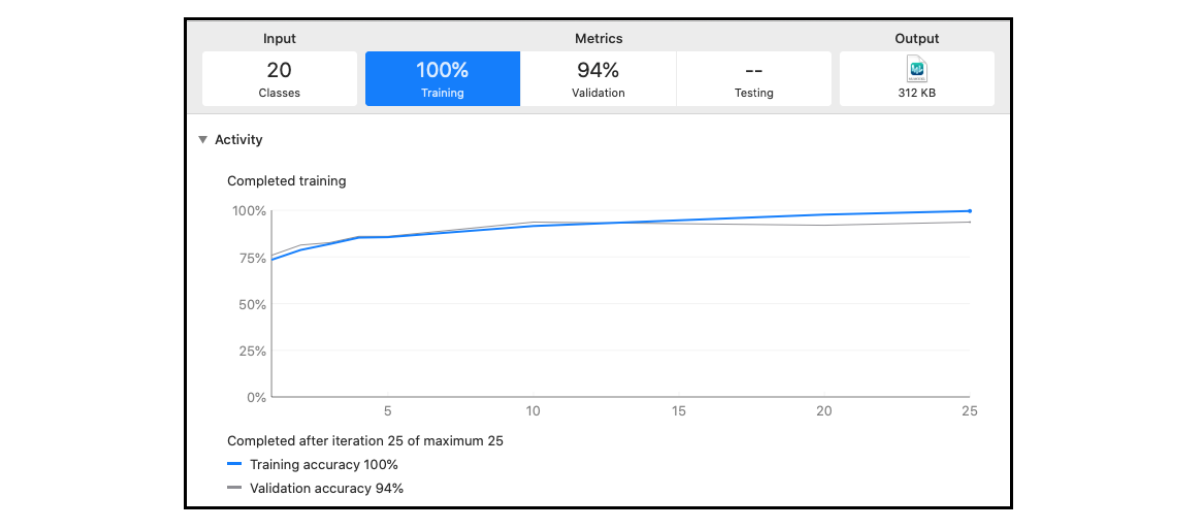
12 번의 반복(iterations) 이후, 검증 정확도(validation accuracy)는 94%로 낮아진다. 즉, 100 개의 교육 예제(training examples) 중 94 개에 대한 범주(class)를 정확하게 예측한다. 그러나 훈련 정확도(training accuracy)는 100%로 계속 증가하고 있다. 분류기(classifier)는 10개 중 10개의 이미지를 정확하게 분류한다.
Create ML에서의 반복(iteration)은 “에포크 (epoch)”라고도 하는 전체 교육 세트(training set)를 통과하는 것이다. 즉, Create ML은 모델(model)에게 모든 4,582개의 모든 훈련 이미지(training images)(또는, 모든 훈련 이미지의 추출된 특징 벡터(feature vectors))를 한 번 보여줬음을 의미한다. 반복(iterations)을 10번 수행하면, 모델(model)은 각 학습 이미지(training image)(또는, 특징 벡터(feature vectors))를 10번 보게 된다.
기본적으로 Create ML은 로지스틱 회귀(logistic regression)를 최대 25회 반복(iterations) 학습(trains)하지만, 최대 반복(Maximum Iterations) 매개 변수(parameter)를 사용하여, 이를 변경할 수 있다. 일반적으로 반복 횟수(iterations)가 많을수록 모델(model)이 나아지지만, 훈련(training)에 더 많은 시간이 소요된다. 그러나 로지스틱 회귀(logistic regression) 훈련(training)은 오래 걸리지 않으므로 큰 문제 제가 없다.
특징 추출(feature extraction)을 다시 수행해 본다. Mac에서 5분 이내에 특징 추출(feature extraction)을 완료한 경우, 반복(iterations) 횟수를 줄이면 어떻게 되는지 확인해 본다 :
- + 버튼을 클릭하여, 새 Model Source 를 추가한다 : 시작 창(start window)으로 돌아간다.
- Training Data Choose 메뉴에서 train를 선택한다. Validation Data의 Automatic 설정을 확인한다. 검증(validation) 이미지를 따로 추가해 사용할 수도 있다.
- Max iterations을 10으로 줄인다.
- Train을 클릭한다.

특징(features) 추출에 거의 모든 교육 시간(training time)이 사용되는 것을 볼 수 있다. Turi Create를 사용하면 추출된(extracted) 특징(features)을 저장(save)하여, 기다릴 필요없이 다른 학습(training) 매개 변수(parameters)를 시도해 볼 수 있다.
여기서는 반복(iterations)을 10회로 줄인 결과, 2분 38초 후에 교육(training)이 완료되어 25회 반복(iterations)에 비해 9 초가 단축되었다. 그러나 정확도(accuracy)는 훨씬 낮다.

훈련 정확도(training accuracy, 92%)는 검증 정확도(validation accuracy, 89%)보다 더 감소했지만, 두 값은 더 가까워졌다(3%).
이번에는 Create ML이 검증 데이터로 학습 데이터에서 무작위로(random) 5%를 선택하지 않고, 범주(class) 당 약 50개의 이미지가 있는 snacks / val 하위 폴더(subdirectory)를 사용할 때 어떤 일이 발생하는지 확인한다.
세 번째 Model Source를 추가하고, 이름을 Multisnacks manual val로 변경한다. 다른 두 개의 이름도 Multisnacks 25 iter와 Multisnacks 10 iter로 바꿔준다.
Multisnacks manual val에서 Training Data를 train로 선택하고, Validation Data를 snacks/val로 선택한다 :

Max iterations는 25회로 두고, Train을 클릭한다.
결과는 다음과 같다 :

여기서는 240개가 아닌 955개의 검증(validation) 이미지와, 4,838개의 훈련(training) 이미지를 모두 사용했다. 그러나 검증 정확도(validation accuracy)는 더 나빠졌기에, 모델(model)이 과적합(overfitting) 되었음을 알 수 있다.
Overfitting happens
과적합(Overfitting)은 기계 학습(machine learning)에서 자주 사용하는 용어(term)로 모델(model)이 특정 훈련(training) 이미지를 기억하기 시작했음을 의미한다. 예를 들어, train/ice cream/b0fff2ec6c49c718.jpg 이미지에는 파란 셔츠를 입은 사람이 선디를 먹고 있다 :

분류기(classifier)가 "이미지에 큰 파란색 덩어리(blob)가 있으면, 이 범주(class)는 아이스크림이다"라는 규칙을 배우고 있다고 가정한다. 파란색 셔츠는 일반적으로 아이스크림과 아무런 관련이 없으므로 모델(model)이 학습하고자 하는 것은 아니다. 그것은 단지 이 특정 훈련(training) 이미지에서만 효과가 있다.
이것이 훈련(training)에 사용하지 않는 이미지 세트를 검증(validation) 이미지로 사용하는 이유이다. 모델(model)은 이전에 이러한 이미지를 본 적이 없고 이에 대해 전혀 학습(learned)하지 못했으므로, 훈련된 모델(model)이 새로운 이미지를 얼마나 잘 일반화(generalize)할 수 있는지 확인할 수 있는 좋은 테스트이다.
따라서이 특정 모델(model)의 실제 정확도(correct)는 98%(훈련 정확도(training accuracy))가 아니라 92%(검증 정확도(validation accuracy))이다. 훈련 정확도(training accuracy)만 살펴보면, 모델(model)의 정확도(accuracy) 추정치(estimate)가 너무 낙관적(optimistic)일 수 있다. 이상적으로는 10회 반복(iterations) 모델 같이 검증 정확도(validation accuracy)가 훈련 정확도(training accuracy)와 유사해야 하는데, 이는 모델(model)이 제대로 작동하고 있다는 것을 의미한다.
일반적으로 검증 정확도(validation accuracy)는 훈련 정확도(training accuracy)보다 약간 낮지만, 그 차이가 너무 크면 모델(model)이 훈련 세트(training set)에서 관련없는 세부 사항을 너무 많이 학습했다는 의미이며, 특정 훈련(training) 이미지에 대해 어떤 결과가 나와야 하는지 암기(memorizing)한다. 과적합(Overfitting)은 딥 러닝(deep learning) 모델(model)을 훈련(training)할 때 가장 일반적인(prevalent) 문제 중 하나이다.
과적합(overfitting)을 처리하는 방법은 여러 가지가 있다. 가장 좋은 전략은 더 많은 데이터로 훈련(train)하는 것이다. 안타깝게도 여기서는 100GB의 데이터 세트(dataset)를 다운로드 할 수 없으므로, 상대적으로 작은 데이터 세트(dataset)를 사용한다. 이미지 분류기(image classifiers)의 경우 이미지를 반전(flipping), 회전(rotating), 기울기(shearing), 노출(exposure) 변경 등을 사용하여 이미지 데이터를 보강(augment) 할 수 있다. 데이터 보강(augment)에 대한 예시는 다음과 같다 :
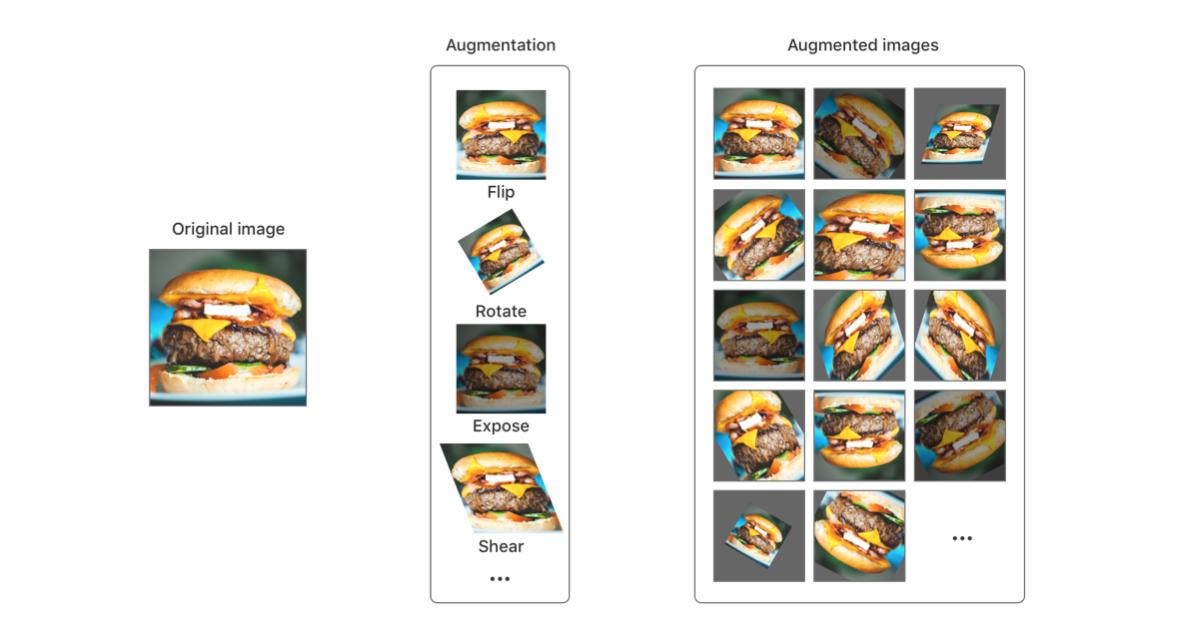
새 Model Source를 추가해 이름을 Multisnacks crop로 지정한 다음, 이전과 같이 옵션을 설정하고 몇 가지 데이터 보강(augmentation)을 선택한다 :

보강(augmentation) 옵션(options)은 알파벳(alphabetical) 순서대로 나열되지만, Xcode 11 이전 버전의 옵션(options) 창에서는 교육 효과가 가장 큰 것부터 나열되며, Crop이 가장 먼저 오게 된다.

이 순서는 둘 이상의 옵션(options)을 선택할 경우, 분류기(classifier)가 옵션을 적용하는 순서이기도 하다. 자르기(Crop)를 선택하면 각 원본에 대한 4개의 뒤집힌(flipped) 이미지가 생성되므로, 특징 추출(feature extraction)이 거의 5배가 더 오래 걸린다. 6개의 보강(augmentation) 옵션(options)을 모두 선택하면, 각 원본에 대해 100개의 보강(augmented)된 이미지가 만들어 진다. 보강(augmented) 이미지의 수는 100개로 제한되기 때문에 실제로는 "100 개 만(only 100)" 이다.
Train을 눌러 훈련을 시작한다.
결과는 다음과 같다 :

훈련 정확도(training accuracy)는 약간 낮지만(97%) 검증 정확도(validation accuracy, 91 %)는 약간 개선되었다. 하지만 여전히 과적합(overfitting)이며, 약 25,000개의 이미지를 사용했기 때문에 학습(learn)이 더 오래 걸린다.
또 다른 개선 방법은 모델(model)에 정규화(일반화, regularization)를 추가하는 것이다. 이는 몇 가지 특징(features)에 큰 가중치(weights)를 부여하는 모델이 과적합(overfitting)될 가능성이 높기 때문에, 큰 가중치(weights)에 불이익(penalizes)을 주는 것이다. Create ML은 정규화(regularization)를 수행할 수 없다. 차후에 Turi Create를 사용해 적용한다.
훈련 정확도(training accuracy)는 유용한 지표(metric)이지만, 이는 모델(model)이 실제로 얼마나 잘 작동하는지가 아니라 새로운 것을 잘 배우고 있는지에 대한 척도이다. 실제 사용자의 입장에서는 교육(training) 이미지의 범주(classes)가 무엇인지 이미 알고 있기 때문에, 그에 대한 좋은 점수가 그다지 흥미롭지 않다.
우리가 신경 쓰는 것은 모델이 이전에 보지 못했던 이미지에서 얼마나 잘 작동하는지이다. 따라서, 주시해야하는 측정 기준(metric)은 실제 세계에서 모델(model) 성능을 나타내는 좋은 지표(indicator)인 검증 정확도(validation accuracy)이다.
과적합(overfitting)이 검증 정확도(validation accuracy)가 훈련 정확도(training accuracy)보다 낮을 경우의 유일한 이유는 아니다. 교육(training) 이미지가 검증(validation) 이미지와 근본적으로(fundamental) 다른 경우(예시 : 모든 교육(training) 이미지는 야간에 촬영되었고, 모든 검증(validation) 이미지는 낮에 촬영됨), 모델(model)은 분명히 좋은 검증(validation) 점수를 받지 못한다. 교육(training)에 사용되지 않았지만, 동일한 종류의 객체를 포함하고 있다면 검증(validation) 이미지의 출처는 중요하지 않다. 이것이 Create ML이 검증(validation)에 사용할 이미지로, 훈련(training) 이미지의 5%를 무작위(randomly)로 선택하는 이유이다. 다음 장에서 과적합(overfitting)과 훈련(training) 및 검증(validation) 정확도(accuracies)의 차이점에 대해 자세히 살펴 본다.
More metrics and the test set
모델(model)이 학습(trained)을 마쳤으므로, 이전에 본 적없는 새로운 이미지에 대해 얼마나 잘 작동하는지 확인하는 것이 좋다. 훈련(training) 중, 검증 정확도(validation accuracy)로 간단하게 확인했지만, 새로운 데이터 세트를 사용해 검사해 본다. 데이터 세트(dataset)의 snacks/test 폴더(folder)에는 교육(training) 데이터와 같은 범주(class)이름으로 정리된 아직 사용하지 않은 테스트(test) 이미지가 있다.
검증(Validation) 정확도(accuracy)가 가장 높은 모델 소스(Model Source)로 전환한다. 여기서는, 검증 정확도(validation accuracy)가 94%인 25 iter 모델을 선택한다.
Testing 탭을 선택한 다음, snacks/test를 선택한다 :

Test Model을 클릭한다 : 시간이 조금 걸린다. 훈련(training)과 마찬가지로 이미지의 특징 추출(feature extraction)은 분류(classification)보다 시간이 더 걸린다.

정확도가 88%로 검증 정확도(validation accuracy)보다 낮다.
교육 중에 사용되는 검증(validation) 세트와 현재 사용 중인 테스트(test) 세트 모두 훈련된 모델(model)이 새 이미지에 대해 얼마나 제대로 수행되는지 확인하는데 사용된다.
그러나 검증(validation) 세트는 학습 알고리즘(learning algorithm)의 설정(hyperparameters)을 조정하는 데에도 종종 사용된다. 때문에 훈련(training) 과정에서 이러한 이미지를 직접 보지 않았더라도, 모델(model)은 검증(validation) 세트 이미지에 영향을 받는다. 따라서 검증(validation) 점수(score)는 훈련 정확도(training accuracy)보다 모델(model)의 실제 성능을 잘 표현하지만, 여전히 완전하지는 않다(impartial). 따라서 별도의 테스트(test) 세트를 준비하는 것이 좋다. 이상적으로는 훈련(training)이 완료되었을 때, 테스트(test) 세트를 사용해 모델(model)을 한 번만 평가하는 것이 좋다.
테스트 세트(test) 성능을 향상시키기 위해 모델(model)을 수정(tweak)하려는 유혹(temptation)을 이겨내야 한다. 테스트 세트(test set) 이미지가 모델(model) 학습 방법에 영향을 미치는 않기 때문에, 정확도가 상대적으로 낮은 것이 일반적이다. 모델(model)이 아직 완벽하지 않다면 테스트 이후의 수정이 나쁘지 않을 수도 있지만, 습관이 되어서는 안 된다. 테스트 세트(test set)를 마지막으로 저장하고, 가능한 한 몇 번만 평가해야 한다.88%는 10개의 이미지 중 하나 이상을 잘못(wrong) 판단했음을 의미한다. 99%(100개 이미지 중 하나만 잘못 판단함)또는 그 이상의 정확도를 원하지만, 이것의 실현 여부는 모델(model)의 용량(capacity), 범주(classes)의 수, 보유한 교육(training) 이미지 수 등에 따라 달려 있다.
88%는 이상적이지는 않지만, 모델(model)이 꽤 많은 것을 배웠다는 의미이다. 20개의 범주(classes)에 대해 완전히 임의 추측(random guess)하면, 평균 20번 중 한 번 또는 5%만 정확할 것이다. 따라서 모델(model)은 이미 무작위 추측(random guess)보다 훨씬 낫다. 그러나 현재 데이터 세트(dataset)로는 Create ML이 이보다 더 나은 성과를 거두지 못할 것으로 보인다.
정확도 점수(accuracy score)는 확률(probability)이 가장 높은 범주(class)만을 예측한다는 것을 명심해야 한다. 사진에 사과가 포함되어 있지만, 가장 확실한 예측(confident prediction)이 "핫도그"라면 분명히 잘못된 답이다. 그러나 첫 번째 범주(class)가 40%의 "핫도그"이고 두 번째가 39%인 "사과"라면, 이 예측이 올바르다고 생각할 수 있다.
Examining Your Output Model
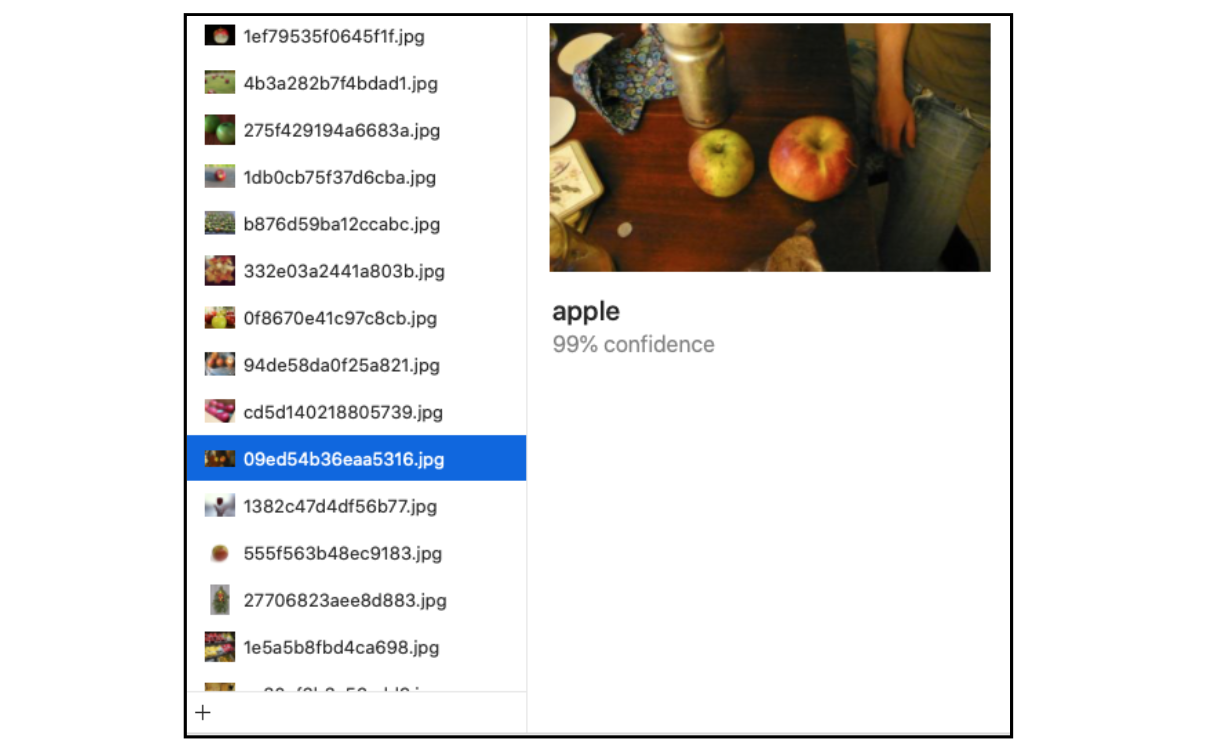
실제 Core ML 모델(model)을 살펴본다. Output 탭(tab)을 선택한 다음, snacks/test 폴더(folder)를 Drag or Add Files 라고 표시된 위치로 끌어다 놓는다. 순식간에 모델(model)이 테스트(test) 이미지를 분류(classifies)한다. 예측된 범주(class)와 모델(model)의 신뢰 수준(confidence level)을 확인하기 위해, 각 범주(class)를 확인(inspect)할 수 있다 :

일부 이미지에 대해서는 모델(model)이 높은 신뢰 점수를 보여주기도 한다 :
모델(model)을 직접 교육(training)하는 것의 핵심은 앱에서 해당 모델(model)을 사용하는 것이므로, 이 새 모델(model) 저장하고, Core ML로 불러와야(load) 한다.
Create ML 앱에서 바탕 화면 또는 Finder의 아무 곳으로 끌어다(drag) 놓으면 된다. 그런 다음 일반적인 방법으로 Xcode에 추가한다. 기존의 .mlmodel 파일을 새 파일로 교체한다. 현재 Snacks 앱에 있는 모델(model)은 SqueezeNet을 기반으로 한 특징 추출기(feature extractor)로 5MB이다. Create ML의 새 모델(model)은 312KB에 불과하다. 실제로는 훨씬 큰 모델(model)이지만, 대부분이 FeatureFeaturePrint_Screen 특징 추출기(feature extractor)로 이미 운영 체제에 포함되어 있기 때문에 .mlmodel 파일의 일부로 배포할 필요가 없다.
Core ML 모델(model)은 일반적으로 특징 추출기(feature extracto)와 로지스틱 회귀 분류기(logistic regression classifier)를 단일 모델(single model)로 결합(combines)한다. 새로운 이미지를 분류해야(classify) 할 경우, 특징 벡터(feature vectors)도 계산해야 하기 때문에 여전히 특징 추출기(feature extractor)가 필요하다. Core ML을 사용하면 로지스틱 회귀(logistic regression)는 신경망(neural network)의 다른 계층(layer)이며, 파이프 라인(pipeline)의 또 다른 단계(stage)일 뿐이다.
그러나 VisionFeaturePrint_Screen을 기반으로 한 Core ML 모델(model)은 특징 추출기(feature extractor)가 iOS의 일부분이기 때문에 따로 포함 할 필요가 없다. 따라서 Core ML 모델은 기본적으로 로지스틱 회귀 분류기(logistic regression classifier)에 불과하며, 크기가 매우 작다.
이 두 특징 추출기(feature extractors)에는 몇 가지 차이점이 있다. SqueezeNet은 227 × 227 이미지를 사용하는 비교적 작은 사전 훈련 모델(pre-trained model)로 1,000개의 특징(features)을 추출(extracts)한다. VisionFeaturePrint_Screen은 299 × 299 이미지를 사용하여 2,048 개의 특징(features)을 추출(extracts)한다. 따라서 Vision 모델(model)을 사용해 이미지에서 추출한 지식이 훨씬 더 풍부하며, 그렇기 때문에 Create ML로 훈련한(trained) 모델(model)이 검증 정확도(validation accuracy)가 67%에 불과한 이전의 SqueezeNet 기반 모델(model)보다 뛰어나다.
Classifying on live video
여기서 사용하는 프로젝트는 지금까지 작업한 앱과 달리, 카메라의 라이브 비디오(live video)에서 작동한다. VideoCapture 클래스(class)는 AVCaptureSession을 사용하여 초당 30프레임(frames)으로 iPhone 카메라의 비디오(video) 프레임(frames)을 읽는다. ViewController는 이 VideoCapture 클래스(class)의 대리자(delegate) 역할을 하며, CVPixelBuffer 객체(object)와 함께 초당 30회 호출된다. Vision을 사용하여 예측(prediction)한 다음 이를 화면에 레이블(label)로 표시한다.
UIImagePicker가 없는 것을 제외하면 코드의 대부분은 이전 앱과 동일하며, 여전히 분류기(classifier)를 사용한다.

앱의 초당 프레임(frames) 수를 계산하는 FPSCounter 객체(object)도 있다. VisionFeaturePrint_Screen을 특징 추출기(feature extractor)로 사용하는 모델(model)을 최신 기기(device)에서 실행하면 30FPS가 된다.
이 앱의 videoCapture.frameInterval 설정을 사용하면, 배터리(battery) 전원을 절약하기 위해 분류기(classifier)의 실행 빈도를 조정할 수 있다. Xcode의 에너지 사용(energy usage) 화면을 확인해 해당 설정을 실험해 볼 수 있다.
VideoCapture 클래스(class)는 카메라에서 비디오를 읽는 방법을 보여주는 간단한 예시(bare bones)이다. 예제 앱이 너무 복잡하지 않도록 의도적으로 단순하게 구현했다. 실제 앱에 사용하려면 중단(interruptions)을 처리하고, 자동 초점(auto-focus), 전면 카메라(front-facing camera) 등의 더 많은 카메라 기능을 추가해야(robust) 한다.
Recap
Create ML을 사용하여 자신만의(own) Core ML 모델(model)을 학습(training)하는 방법을 살펴보았다. 데이터 세트(dataset)가 제한되어 있기 때문에 기본 설정(default settings) 모델의 정확도(accuracy)는 약 90%에 불과하다. 최대 반복 횟수(max iterations)를 늘리면 훈련 정확도(training accuracy)는 향상되지만, 검증 정확도(validation accuracy)는 90% 정도에 머무르고(stuck) 과적합(overfitting)이 발생할 수 있다. 반전된(flipped) 이미지를 추가하고 데이터를 보강(augmenting)해, 교육(training) 정확도와 검증(validation) 정확도(accuracies) 사이의 격차를 줄였지만, 정확도를 높이려면 더 많은 반복(iterations)이 필요하다.
이미지는 많을 수록 좋다. 여기서는 4,800개의 이미지를 사용했지만, 48,000개가 있다면 더 좋았을 것이고, 480만 개가 있었다면 더더욱 좋았을 것이다. 그러나 교육(training) 이미지를 찾고 주석을 달 때(annotating) 실제 비용이 발생하며, 대부분의 프로젝트(project)에서는 q범주(class)당 수백 또는 수천 개의 이미지만 있으면 충분하다. 얻은 자료는 충분히 사용해야 한다. 더 많은 교육(training) 데이터를 수집 한 후, 언제든지 모델(model)을 다시 학습(retrain)할 수 있다. 기계 학습(machine learning)에서 데이터가 가장 중요하며, 많은 데이터가 있을 수록 대개 더 나은 모델(model)을 만들 수 있다.
Create ML은 매우 사용하기 쉽지만 교육(training) 과정의 일부만 조정(tweak)할 수 있고, 현재는 이미지와 텍스트 분류(classification) 모델(model)에만 한정되어 있다.
Turi Create를 사용하면 더 많은 작업 중심 모델(task-focused models)을 맞춤화(customize)하고, 교육(training) 과정에서 더 많은 조정(hands-on)을 할 수 있다. Create ML만큼 사용하기 쉽지만 Python으로 작성해야 한다.
Challenge
레이블(label)이 지정된 이미지의 데이터 세트(dataset)를 직접 작성하고, Create ML을 사용하여 모델(model)을 교육(train)한다.
Kaggle의 dogs vs. cats 대회(competition) www.kaggle.com/c/dogs-vs-cats의 데이터 세트(dataset)를 사용해 개와 고양이를 구분하는 이진 분류기(binary classifier)를 훈련(train)시킬 수 있다. 최상의 모델(model)은 약 98%의 정확도(accuracy)를 보여준다.
Kaggle의 다른 이미지 데이터 세트(datasets)도 확인해 본다 :
자신만의 모델(model)을 만들어 iOS 앱에 활용할 수 있다.
Key points
- macOS의 playgrounds를 사용하여, Create ML을 테스트하고 설정을 변경하여 간단한 기계 학습 모델(machine learning models)을 만들 수 있다.
- Create ML을 사용하면, iOS 12 이상의 장치(device)에 이미 내장된 Vision 특징 추출기(feature extractor)를 활용하는 소형 모델(model)을 만들 수 있다.
- 검증 정확도(validation accuracy)와 훈련 정확도(training accuracy)가 유사한 것이 이상적(Ideally)이다.
- 과적합(overfitting)을 처리하는 여러 가지 방법이 있다 : 더 많은 이미지 포함, 훈련(training) 반복(iterations) 횟수 증가, 데이터 보강(augment) 등
- 정밀도(precision)와 재현율(recall)은 모델(model)을 평가하는 유용한 측정 기준(metrics)이다.
'Raywenderlich > Machine Learning by Tutorials' 카테고리의 다른 글
Chapter 5: Digging Deeper into Turi Create (0) 2020.05.12 Chapter 4: Getting Started with Python & Turi Create (0) 2020.05.10 Chapter 2: Getting Started with Image Classification (0) 2020.04.28 Chapter 1: Machine Learning, iOS & You (0) 2020.04.24