-
Chapter 22: The Heap Data StructureRaywenderlich/Data Structures & Algorithms in Swift 2020. 3. 5. 22:42
인형 뽑기 기계에서 원하는 경품을 뽑는 것 처럼, 원하는 요소에 집중하는 것이 힙(Heap) 자료구조(Data Structure)의 본질이다.

힙(heap)을 사용하면, Collection에서 최소(minimum) 및 최대(maximum) 요소(element)를 쉽게 가져올 수 있다.
What is a heap?
힙(heap)은 배열(Array)을 사용하여, 구성할 수 있는 완전(complete) 이진 트리이다.
완전 이진 트리 : 마지막 level을 제외한 모든 level의 노드(node)가 모두 채워져 있으며, 마지막 level의 모든 노드는 왼쪽 부터 순서대로 채워져 있다.
포화 이진 트리(perfect binary tree) : 완전 이진 트리에서 마지막 level까지 모두 채워져 있는 트리
https://ko.wikipedia.org/wiki/%EC%9D%B4%EC%A7%84_%ED%8A%B8%EB%A6%ACmemory heap과는 다른 개념이다. memory heap은 pool of memory를 지칭하는 개념이다.
힙(heap)은 두 가지 종류가 있다.
- Max heap(최대 힙) : 값이 클수록 우선 순위(higher property)가 높다. 상위 node가 항상 큰(higher) 값(value)을 가진다. root는 최대값이 된다.
- Min heap(최소 힙) : 값이 작을수록 우선 순위(higher property)가 높다. 상위 node가 항상 작은(lower) 값(value)을 가진다. root가 최소값이 된다.
The heap property
힙(heap)은 항상 만족해야 하는 중요한 특성이 있다. 이를 힙 불변성(heap invariant) 또는 힙 속성(heap property) 이라 한다.

최대 힙(max heap)에서 상위 노드(node)는 항상 자식(child)의 값(value)보다 크거나 같은 값을 가져야 한다. root 노드(node)는 항상 가장 큰 값을 가진다. 최소 힙(min heap)에서 상위 노드(node)는 항상 자식(child)의 값(value)보다 작거나 같은 값을 가져야 한다. root 노드(node)는 항상 가장 작은 값을 가진다.

힙의 또 다른 중요한 특징은 완전 이진 트리(complete binary tree)라는 것이다. 즉, 마지막 level을 제외한 모든 level이 채워져 있어야 한다. 현재 단계를 완료하기 전에 다음 단계로 넘어갈 수 없는 게임과 비슷하다.
Heap applications
힙(heap)을 사용하는 예시는 다음과 같다.
- Collection의 최소값 또는 최대값 요소 계산
- 힙 정렬(Heap sort)
- 우선 순위 큐(priority queue) 구성
- Prim 또는 Dijkstra와 같은 그래프 자료구조 알고리즘을 우선 순위 큐(priority queue)를 사용해 구현
Common heap operations
기본 힙(heap)을 정의하는 것부터 시작한다.
struct Heap<Element: Equatable> { var elements: [Element] = [] let sort: (Element, Element) -> Bool init(sort: @escaping (Element, Element) -> Bool) { self.sort = sort } }힙(heap)의 요소를 보유하고 있는 배열(Array)과 힙(heap)을 정렬(sort)하는 방법을 정의하고 있는 정렬 함수가 포함된다. initializer에서 적절한 함수를 전달해 최소 힙(min heap)과 최대 힙(max heap)을 모두 생성할 수 있다.
How do you represent a heap?
트리(tree)에는 자식(child)에 대한 참조를 저장하는 노드(node)가 있다. 그리고 이진 트리는 왼쪽(left)과 오른쪽(right) 자식(child)에 대한 참조를 가지고 있다. 힙(Heap)은 실제로는 이진트리이지만, 간단히 배열(Array)로 표현할 수 있다. 이는 트리(tree)를 만드는 특이한 방법인 것처럼 보인다. 그러나 배열을 사용하는 이런 힙 구현의 이점 중 하나는 힙의 요소가 모두 메모리에 연이어 저장되므로(Array) 효율적인 시간, 공간 복잡도를 가진다는 것이다. 요소를 교환(swap)하는 것이 힙의 중요한 부분인데, 이 역시 이진 트리보다 배열(Array)로 구현하는 것이 더 쉽다. 배열을 사용해 힙을 어떻게 나타낼 수 있는지 살펴본다.

힙(heap)을 배열(array)로 나타내려면, 각 level의 요소(element)를 왼쪽부터 오른쪽으로 반복하면 된다. 위의 힙을 배열로 나타내면 다음과 같다.

level이 증가하면, 이전 level보다 필요한 노드(node)가 두 배 많아 진다. 배열(Array)로 구현하면, 힙(heap)의 모든 노드(node)에 쉽게 액세스할 수 있다. 트리(tree)에서의 순회 대신, 간단한 공식을 사용해 Array의 node에 액세스할 수 있다.
0부터 시작하는 index i가 있다고 하면
- 해당 노드(node)의 왼쪽 자식(left child)은 2i + 1 이다.
- 해당 노드(node)의 오른쪽 자식(right child)은 2i +2 이다.
- 해당 노드(node)의 부모 노드(parent node)는 floor((i-1)/2) 이다.

node의 왼쪽(left), 오른쪽(right) 자식(child)을 확인하기 위한 이진트리의 순회는 O(log n) 연산이다. 하지만 배열(Array)과 같은 임의 접근(random-access) 자료구조(data structure)에서 동일한 작업은 O(1) 이다.
이를 고려하여, 위에서 구현한 기본 힙(heap)에 몇 가지 속성과 메서드를 추가한다.
extension Heap { var isEmpty: Bool { elements.isEmpty } var count: Int { elements.count } func peek() -> Element? { elements.first } func leftChildIndex(ofParentAt index: Int) -> Int { //해당 node의 left child는 2i + 1 이다. (2 * index) + 1 } func rightChildIndex(ofParentAt index: Int) -> Int { //해당 node의 right child는 2i +2 이다. (2 * index) + 2 } func parentIndex(ofChildAt index: Int) -> Int { //해당 node의 parent node는 floor((i-1)/2) 이다. (index - 1) / 2 } }다음으로 힙(heap)의 주요 연산들을 구현한다.
Removing from a heap
기본적인 제거(basic remove) 연산(operation)은 단순히 힙(heap)에서 root 노드(node)를 제거하면 된다. 최대 힙(max heap)에서는 다음과 같다.

최대 힙에서는 root 노드(node)의 최대값(maximum value)을 제거한다. 이 작업을 위해서는 먼저, root 노드(node)와 힙(heap)의 마지막(last) 요소를 교환(swap)해야 한다.
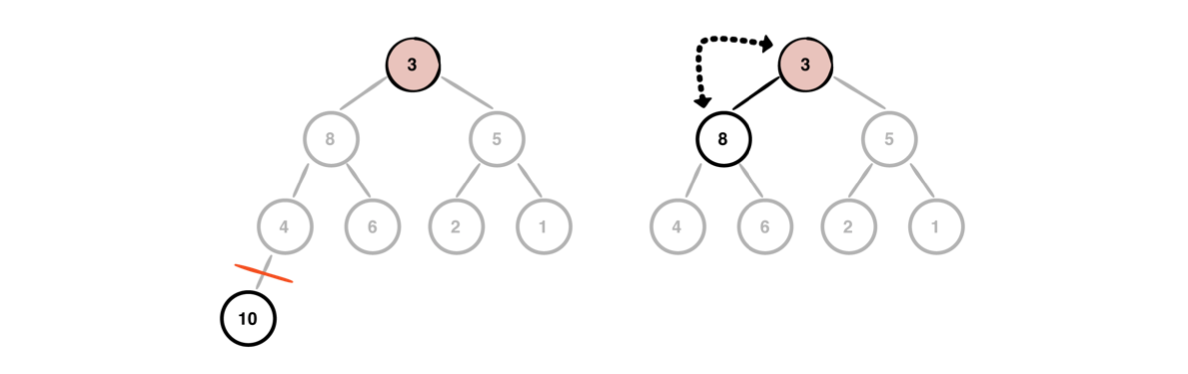
교환(swap) 이후, 마지막 요소(이전의 root, 최대값)을 제거하고, 필요한 경우 이 값(value)을 따로 저장하여 반환할 수 있다. 삭제 이후, 최대 힙(max heap)의 무결성(integrity)을 확인해야 한다. 최대 힙은 모든 상위 노드(node)의 값(value)이 하위 노드(node)의 값(value)보다 크거나 같아야 하는데, 위의 예시는 요소 제거 이후 이 규칙에 위배되므로 sift down(선별)이 필요하다.
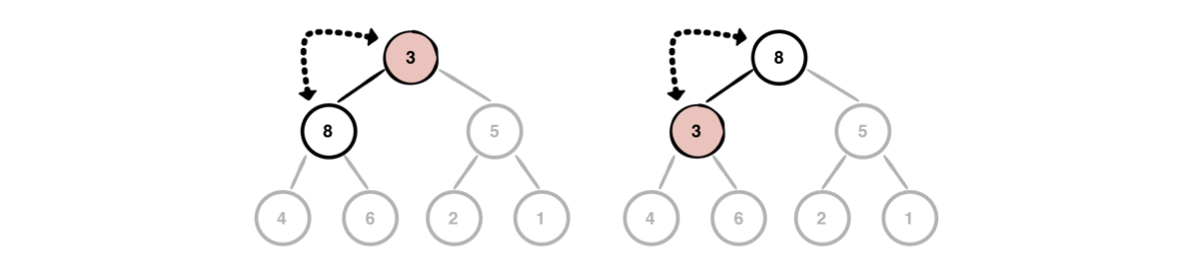
선별(sift down)을 수행하려면 현재 값(3, 현재 root, 이전의 마지막 요소)부터 시작하여 왼쪽과 오른쪽 자식(child)를 확인해야 한다. 두 자식(child) 중 하나의 값(value)이 현재 값(value)보다 큰 경우, 해당 노드를 부모(parent) 노드와 교환(swap)한다. 양쪽 자식(child)의 값(value)이 모두 부모(parent)의 값(value)보다 크다면, 둘 중 더 큰 값(value)을 가진 노드(node)와 부모 노드(node)를 교환(swap)한다.

이제, 노드(node)의 값(value)이 자식(child) 노드(node)의 값(value)보다 크지 않을 때까지 계속해서 선별(sift down)해야 한다.

이렇게 마지막 level에 도달하게 되면, 최대 힙(max heap)의 조건을 다시 만족하게 된다.
Implementation of remove
코드로 구현하면 다음과 같다.
extension Heap { mutating func remove() -> Element? { guard !isEmpty else { //heap이 비어 있다면 nil을 반환한다. return nil } elements.swapAt(0, count - 1) //root와 heap의 마지막 요소를 swap한다. defer { //defer 블록은 코드 흐름과 상관없이 가장 마지막에 실행되는 코드이다. siftDown(from: 0) //swap과 마지막 요소 제거 이후 heap이 최대 또는 최소 heap 조건을 준수하는지 sift down으로 확인한다. } return elements.removeLast() //마지막 요소(swap전의 root. heap의 최대값 혹은 최소값)을 제거하고 반환한다. } }remove() 메서드 뒤에 이어서 선별(sift down) 메서드를 구현해 준다.
extension Heap { mutating func siftDown(from index: Int) { var parent = index //parent의 index를 저장한다. while true { //반환(return) 될 때 까지 계속 반복 let left = leftChildIndex(ofParentAt: parent) //leftChild의 index를 가져온다. let right = rightChildIndex(ofParentAt: parent) //rightChild의 index를 가져온다. var candidate = parent //어떤 index의 node를 parent와 swap할 지 tracking 한다. if left < count && sort(elements[left], elements[candidate]) { //left child의 우선 순위가 parent보다 높은 경우 candidate = left } if right < count && sort(elements[right], elements[candidate]) { //right child의 우선 순위가 candidate(left 혹은 parent)보다 높은 경우 candidate = right } if candidate == parent { //candidate가 parent인 경우는 끝까지 도달한 경우이다. 힙 조건을 만족한다. return //loop 종료 } elements.swapAt(parent, candidate) //swap parent = candidate //새 parent를 지정해 준다. } } }remove()의 전체 시간 복잡도는 O(lon n)이다. 배열(Array)에서 요소를 바꾸는 데 O(1)이 걸리고, 선별(sift down)에 O(log n)이 걸린다.
다음으로 추가(add)연산을 구현한다.
Inserting into a heap
위의 예시 힙(heap)에 7을 삽입(insert)한다고 가정한다.

먼저, heap의 끝에 값(value)을 추가한다.

그리고 최대 힙(max heap)의 조건을 확인한다. 방금 삽입한 노드(node)가 부모(parent)보다 우선 순위(priority)가 높을 수 있으므로 선별 작업이 필요하다. 하지만 이전 remove()에서의 siftDown과는 반대로 삽입한 노드(node)와 부모 노드(parent node)의 우선 순위를 비교하면서 위로 올라간다(sift up). 방향을 제외하면, siftDown과 유사하다.

최대 힙(max heap)의 조건을 충족한다.
Implementation of insert
코드로 구현하면 다음과 같다.
extension Heap { mutating func insert(_ element: Element) { elements.append(element) siftUp(from: elements.count - 1) } }remove()에서의 siftDown과 대칭되는 siftUp을 사용한다.
extension Heap { mutating func siftUp(from index: Int) { var child = index var parent = parentIndex(ofChildAt: child) while child > 0 && sort(elements[child], elements[parent]) { elements.swapAt(child, parent) child = parent parent = parentIndex(ofChildAt: child) } } }구현은 매우 간단하다.
- 요소를 배열(Array)에 추가(append)한 후, sift up을 해 준다.
- siftUp은 현재 노드(node)가 상위 노드(node)보다 우선 순위가 높을 경우 현재 노드를 상위 노드와 교환(swap)한다.
insert(_:)의 전체 시간 복잡도는 O(lon n)이다. 배열(Array)에서 요소를 추가하는 것은 O(1)이 걸리고, sift up에 O(log n)이 걸린다.
이전의 remove() 연산은 root의 요소를 제거했다. 다음은 힙(heap)에서 임의(arbitrary)의 요소를 제거하는 remove 연산을 구현한다.
Removing from an arbitrary index
힙(heap)에서 해당 index의 요소(element)를 제거한다.
extension Heap { mutating func remove(at index: Int) -> Element? { guard index < elements.count else { //index가 Array 범위 밖에 있는지 확인한다. return nil } if index == elements.count - 1 { //마지막 요소를 제거하는 경우에는 별도의 작업이 필요 없다. return elements.removeLast() } else { //마지막 요소가 아니라면 elements.swapAt(index, elements.count - 1) //해당 요소를 마지막 요소와 swap한다. defer { //defer 블록은 코드 흐름과 상관없이 가장 마지막에 실행되는 코드이다. siftDown(from: index) siftUp(from: index) //siftDown과 siftUp를 수행하여 heap을 조정한다. } return elements.removeLast() //마지막 요소(이전의 index node)를 반환하고 제거한다. } } }siftDown과 siftUp를 모두 호출해야 한다. 5를 제거한다고 가정하면, 마지막 요소인 8과 교환(swap)하고 sift up을 연달아 호출해, 힙 조건을 충족하는지 확인해야 한다.

7을 제거한다고 가정하면, 7을 마지막 요소인 1과 교환(swap)하고, sift down을 연달아 호출해, 힙 조건을 충족하는지 확인해야 한다.

힙(heap)에서 임의의 요소를 제거하는 것은 O(log n)이다. 하지만 제거하려는 요소의 index를 찾을 방법이 아직 없다.
Searching for an element in a heap
삭제하려는 요소(element)의 index를 찾으려면 힙(heap)에서 검색을 수행해야 한다. 하지만 불행히도 heap은 빠른 검색을 목적으로 고안된 자료구조가 아니다. 이진 탐색 트리(BST)를 사용하면 순회에 O(log n)이 걸리지만 heap은 배열(Array)을 사용하고, 배열의 요소도 정렬되어 있지 않기 때문에 이진 탐색(binary search)을 수행할 수 없다.
힙(Heap)에서 요소를 검색하는 것은 최악의 경우 배열(Array)의 모든 요소를 확인해야 하므로 O(n)이 된다.
extension Heap { func index(of element: Element, startingAt i: Int) -> Int? { if i >= count { //index가 Array 요소의 수보다 크거나 같으면 검색에 실패한 것이다. return nil } if sort(element, elements[i]) { //찾는 요소가 인덱스 i의 현재 요소보다 우선 순위가 높은지 확인한다. return nil //그럴 경우, 찾는 요소는 heap에서 우선 순위가 더 낮아질 수 없다. } if element == elements[i] { //찾는 요소가 인덱스 i의 현재 요소와 같으면 i를 반환한다. return i } if let j = index(of: element, startingAt: leftChildIndex(ofParentAt: i)) { //왼쪽 child에서 시작하여 재귀적으로 검색한다. return j } if let j = index(of: element, startingAt: rightChildIndex(ofParentAt: i)) { //오른쪽 child에서 시작하여 재귀적으로 검색한다. return j } return nil //두 검색이 모두 실패하면 검색이 실패한 것이다. } }검색에 O(n)가 걸리지만, 힙(heap)의 특성을 활용해 요소의 우선 순위를 확인하여 검색을 최적화한다.
Building a heap
배열(Array) 힙(heap)을 만들 수 있는 initializer를 추가 한다.
extension Heap { init(sort: @escaping (Element, Element) -> Bool, elements: [Element] = []) { //추가적인 매개변수를 사용해 이미 있는 Array로 heap을 구성한다. self.sort = sort self.elements = elements if !elements.isEmpty { //힙의 특성을 만족시키기 위해, leaf가 아닌 첫 node에서 시작하여 Array를 거꾸로 반복하면서 모든 상위 node를 선별한다. //leaf node를 sift down 하는 것은 의미가 없기 때문에, 요소의 절반(상위 node)만 반복한다. for i in stride(from: elements.count / 2 - 1, through: 0, by: -1) { //stride(from:to:by:) 는 to: 뒤의 경계를 포함하지 않는다. //stride(from:through:by:) 는 through: 뒤의 경계까지 포함한다. siftDown(from: i) } } } }추가된 init는 추가적인 매개변수(parameter)를 사용해 이미 있는 배열(Array)로 힙(heap)을 구성한다. 힙의 특성을 만족시키기 위해, 잎(leaf)이 아닌 첫 노드(node)에서 시작하여 배열(Array)을 거꾸로 반복하면서 모든 상위 노드(node)를 선별(sift down)한다. 잎 노드(leaf node)를 sift down 하는 것은 의미가 없기 때문에, 요소의 절반(상위 node)을 반복해 상위 노드(node)만 제거한다.

Testing
구현을 확인해 본다.
var heap = Heap(sort: >, elements: [1, 12, 3, 4, 1, 6, 8, 7]) //max heap while !heap.isEmpty { print(heap.remove()!) // 12 // 8 // 7 // 6 // 4 // 3 // 1 // 1 }정렬 함수로 >를 사용했기 때문에 최대 힙(max heap)이 되며, remove()를 사용하면 요소(element)가 빌 때까지 하나씩 제거된다. 최대 힙(max heap)이므로, 요소가 가장 큰 값(value)부터 하나씩 제거되며 콘솔에 출력된다.
12
8
7
6
4
3
1
1Key points
- 힙(heap) 연산의 시간 복잡도(time complexity)에 대한 요약은 다음과 같다.
연산(Operations) 시간 복잡도(Time Complexity) remove O(log n) insert O(log n) search O(n) peek O(1) - 힙(heap)은 우선 순위(priority)가 가장 높은(highest) 요소 혹은 가장 낮은(lowest) 요소를 유지하는데 적합한 자료구조(data structure)이다.
- 힙(heap)에서 항목을 삽입(insert)하거나 제거(remove)할 때마다, 우선 순위(priority) 조건을 충족하는지 확인해야 한다.
'Raywenderlich > Data Structures & Algorithms in Swift' 카테고리의 다른 글
Chapter 24: Priority Queue (0) 2020.03.07 Chapter 23: Heap Data Structure Challenges (0) 2020.03.06 Chapter 21: Binary Search Challenges (0) 2020.03.04 Chapter 20: Binary Search (0) 2020.03.03 Chapter 19: Trie Challenges (0) 2020.03.02